Architecture Lab实验解答
1.实验概述
注意:Architecture Lab实验需要用到CSAPP_3th第四章和第五章的内容,尤其是第四章关于处理器架构和程序优化方面的知识,还需要知道汇编语言的编码。
所以实验之前需要掌握第四章和第五章的知识。
本次实验的内容是让我们了解处理器指令集体系的设计和逻辑实现方法,这样让我们更加了解处理器的构造,以便写出更快更好的程序。
这次实验一共有3关,第1关让我们熟悉CSAPP_3th第四章所设计的Y86-64处理器的指令运用,第2关让我们对简单的顺序结构处理器进行指令添加,第3关是让我们结合程序优化和处理器结构方面的知识,对流水线结构处理器的一个算法进行改进,使其达到给定的优化指标。
实验还提供了每一关对应的处理器编译与运行程序等工具。
2.实验准备
本次实验所包含的文档archlab.pdf以及每一关对应文件夹中的README文档详细介绍了每一关所需要进行的步骤、完成的目标和附带工具的使用方法,以供我们参考。
3.进行实验
本次实验主要是对CSAPP_3th第四章所设计的Y86-64处理器指令的设计与运用。
实验相关知识
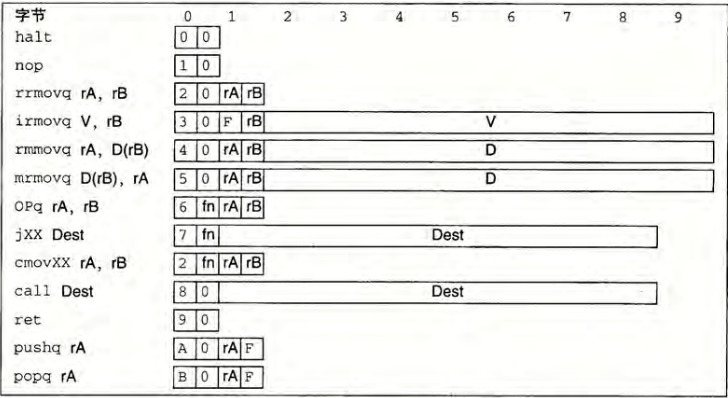
在进行实验之前,我们需要了解本次实验的示例处理器所含的指令集,以下是其所设计的Y86-64处理器的汇编指令集以及相关的伪指令示例:


3.1 第一关
3.11 任务要求
第一关所需的所有工具文件在archlab-handout/sim/misc目录下,本关需要先在目录archlab-handout/sim/misc下使用其中的makefile文件编译所需要使用的处理器编译器和模拟程序。
在终端程序的archlab-handout/sim/misc目录下输入指令make来编译处理器编译器和模拟程序。
本关让我们根据文件examples.c中的三个c语言函数,编写出他们的对应Y86-64处理器的ys后缀的汇编代码,并使之能够正确运行。ys汇编代码文件可以使用该目录的处理器编译器yas编译为yo文件,然后使用模拟程序yis运行该yo文件进行运行,测试汇编代码是否运行正确(模拟程序yis会显示该代码运行后所有变化的寄存器和地址中的值,其中左边是运行前的值,右边是运行后的值)。
只有这三个汇编代码全部正确无误才算完成该关。
3.12 任务解答
我们先来看看文件examples.c中提供的三个c语言函数:
/* 以下为examples.c中的内容*/ /* * Architecture Lab: Part A * * High level specs for the functions that the students will rewrite * in Y86-64 assembly language */ /* $begin examples */ /* linked list element */ typedef struct ELE { long val; struct ELE *next; } *list_ptr; /* sum_list - Sum the elements of a linked list */ long sum_list(list_ptr ls) { long val = 0; while (ls) { val += ls->val; ls = ls->next; } return val; } /* rsum_list - Recursive version of sum_list */ long rsum_list(list_ptr ls) { if (!ls) return 0; else { long val = ls->val; long rest = rsum_list(ls->next); return val + rest; } } /* copy_block - Copy src to dest and return xor checksum of src */ long copy_block(long *src, long *dest, long len) { long result = 0; while (len > 0) { long val = *src++; *dest++ = val; result ^= val; len--; } return result; } /* $end examples */
可以发现函数sum_list和rsum_list是用来计算给定链表中的所有元素之和的,只不过函数sum_list是用循环实现的,而函数rsum_list则是用递归。
函数copy_block是将给定数组的所有元素复制到另一个数组中,并且返回元素值之间的异或值。
其中函数sum_list和rsum_list要用以下链表进行测试:
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
而函数copy_block要用以下两个数组进行测试:
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
3.121 函数sum_list
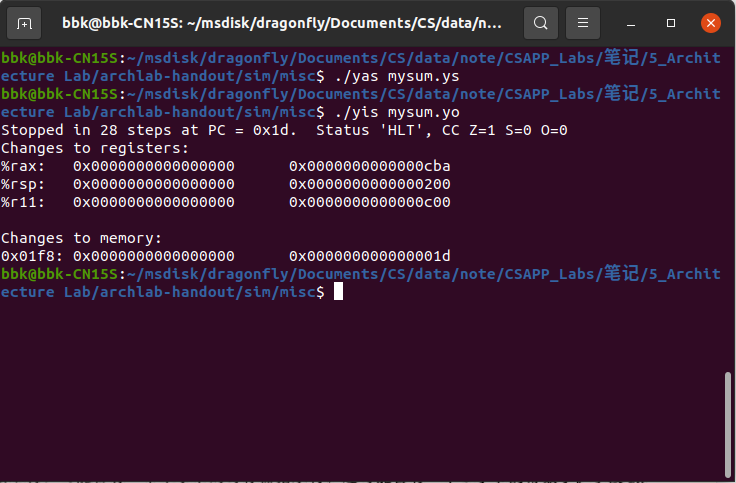
我们可以根据之前提供的伪指令示例来编写汇编代码,要注意因为该模拟处理器的问题,我们的指令必须要从地址0开始,也就是文件开头要写.pos 0,而且也要规定栈地址的起始位置,否则模拟程序yis会运行错误。
因为函数使用循环结构,所以我们可以用通用的循环汇编格式来编写该代码,以下为sum_list的汇编代码:
// 以下为mysum.ys中的内容
.pos 0
irmovq stack, %rsp
irmovq ele1, %rdi
call llist_sum
halt
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
llist_sum:
irmovq $0, %rax
jmp test
loop:
mrmovq 0(%rdi), %r11
addq %r11, %rax
mrmovq 8(%rdi), %rdi
test:
rrmovq %rdi, %r10
andq %r10, %r10
jne loop
ret
.pos 0x200
stack:
以下是该汇编代码运行正确的界面:
3.122 函数rsum_list
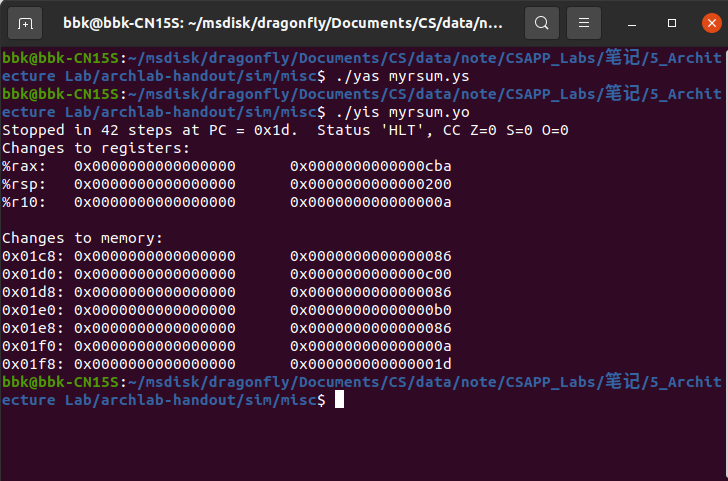
因为函数使用递归结构,所以我们可以用通用的递归汇编格式来编写该代码,以下为rsum_list的汇编代码:
// 以下为myrsum.ys中的内容
.pos 0
irmovq stack, %rsp
irmovq ele1, %rdi
call llist_rsum
halt
.align 8
ele1:
.quad 0x00a
.quad ele2
ele2:
.quad 0x0b0
.quad ele3
ele3:
.quad 0xc00
.quad 0
llist_rsum:
irmovq $0, %rax
rrmovq %rdi, %r11
andq %r11,%r11
je done
mrmovq 0(%rdi), %r10
pushq %r10
mrmovq 8(%rdi), %rdi
call llist_rsum
popq %r10
addq %r10, %rax
done:
ret
.pos 0x200
stack:
以下是该汇编代码运行正确的界面:
3.123 函数copy_block
和之前一样,我们写出各代码对应的汇编格式就可以了,以下为copy_block的汇编代码:
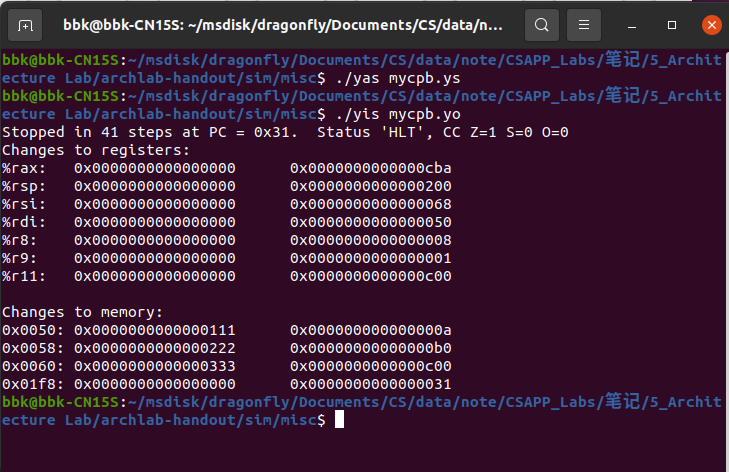
// 以下为mycpb.ys中的内容
.pos 0
irmovq stack, %rsp
irmovq src, %rdi
irmovq dest, %rsi
irmovq $3, %rdx
call cpblock
halt
.align 8
src:
.quad 0x00a
.quad 0x0b0
.quad 0xc00
dest:
.quad 0x111
.quad 0x222
.quad 0x333
cpblock:
irmovq $0, %rax
irmovq $8, %r8
irmovq $1, %r9
jmp test
loop:
mrmovq 0(%rdi), %r11
rmmovq %r11, 0(%rsi)
addq %r8, %rdi
addq %r8, %rsi
xorq %r11, %rax
subq %r9, %rdx
test:
rrmovq %rdx, %r10
andq %r10, %r10
jne loop
ret
.pos 0x200
stack:
以下是该汇编代码运行正确的界面:
3.2 第二关
3.21 任务要求
第二关所需的所有工具文件在archlab-handout/sim/seq目录下。
本关让我们根据CSAPP_3th第四章的某几个作业题对文件seq-full.hcl进行修改,使该Y86-64顺序处理器包含新增的iaddq指令,并在添加新指令后能够正常有效的运行。
以下为CSAPP_3th第四章对应的那些作业题:



在修改完seq-full.hcl文件后,我们需要在目录archlab-handout/sim/seq下使用其中的makefile文件编译该新的处理器模拟程序,其中模拟程序可以选择tty模式和gui模式,gui模式为makefile文件设置的默认模式,gui模式可以进行单步调试,但需要先安装tty等依赖包,所以我选的是tty模式,可以直接编译该程序而不需要安装依赖包。
改为tty模式的操作就是打开makefile文件并注释掉其中的GUIMODE、TKLIBS和TKINC变量。
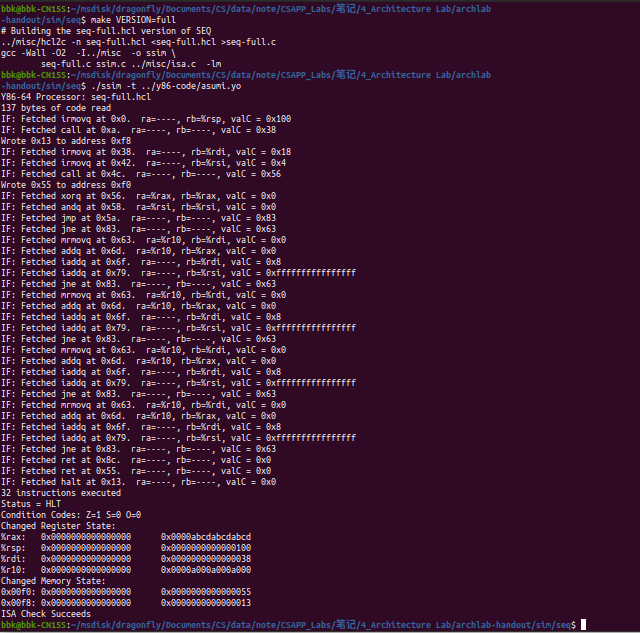
在终端程序的archlab-handout/sim/seq目录下输入指令make VERSION=full来编译新的处理器模拟程序。
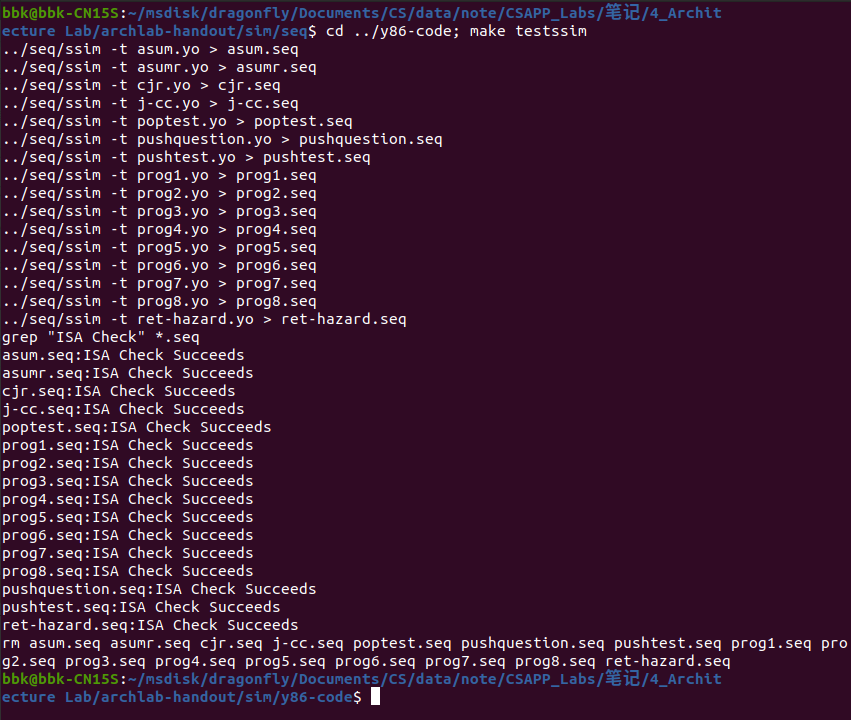
编译出了新的处理器模拟程序后,我们需要两轮的漏洞测试(不会测试新加的指令),测试新加的指令会不会使其处理器模拟程序产生漏洞,在终端程序的archlab-handout/sim/seq目录下先后输入指令./ssim -t ../y86-code/asumi.yo和cd ../y86-code; make testssim来进行小型和大型漏洞测试。
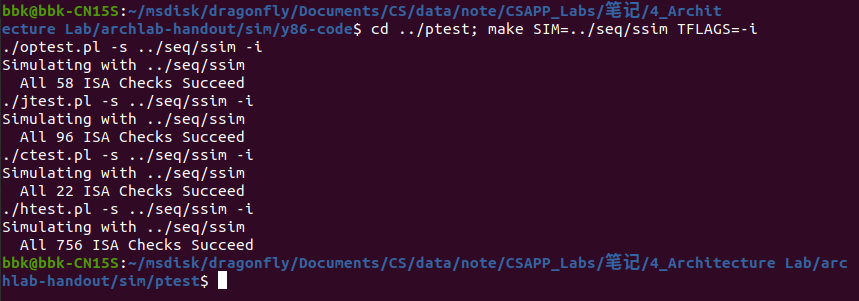
漏洞测试都通过后就可以测试新加指令的逻辑问题了,在终端程序的archlab-handout/sim/seq目录下先后输入指令cd ../ptest; make SIM=../seq/ssim TFLAGS=-i来进行。
只有这三个测试全部通过才算完成该关。
3.22 任务解答
本关需要我们在Y86-64顺序处理器中添加一个新的iaddq指令,该指令是将左边的立即数与右边的寄存器相加,并将其值保存在右边的寄存器中。
通过观察CSAPP_3th第四章中所给的Opt指令流程:
我们可以推测出顺序结构的iaddq指令的流程应该为以下所示:
# iaddq V,rB #phaseFetch # icode:ifun <-- M1[PC] # rB <-- M1[PC+1] # valC <-- M8[PC+2] # valP <-- PC+10 #phaseDecode # valB <-- R[rB] #phaseExecute # valE <-- valC+valB # set CC #phaseMemory # #phaseWriteBack # R[rB] <-- valE #phaseUpdatePC # PC <-- valP
根据推测出的iaddq指令流程,我们就需要在seq-full.hcl文件中添加或修改对应的hcl变量表达式,以下为添加或修改的hcl表达式:
# 以下为修改后的seq-full.hcl中的部分内容 #################################################################### # Control Signal Definitions. # #################################################################### ################ Fetch Stage ################################### # Determine instruction code word icode = [ imem_error: INOP; 1: imem_icode; # Default: get from instruction memory ]; # Determine instruction function word ifun = [ imem_error: FNONE; 1: imem_ifun; # Default: get from instruction memory ]; bool instr_valid = icode in { INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ, IIADDQ }; # Does fetched instruction require a regid byte? bool need_regids = icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ }; # Does fetched instruction require a constant word? bool need_valC = icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL, IIADDQ }; ################ Decode Stage ################################### ## What register should be used as the A source? word srcA = [ icode in { IRRMOVQ, IRMMOVQ, IOPQ, IPUSHQ } : rA; icode in { IPOPQ, IRET } : RRSP; 1 : RNONE; # Don't need register ]; ## What register should be used as the B source? word srcB = [ icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ]; ## What register should be used as the E destination? word dstE = [ icode in { IRRMOVQ } && Cnd : rB; icode in { IIRMOVQ, IOPQ, IIADDQ } : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ]; ## What register should be used as the M destination? word dstM = [ icode in { IMRMOVQ, IPOPQ } : rA; 1 : RNONE; # Don't write any register ]; ################ Execute Stage ################################### ## Select input A to ALU word aluA = [ icode in { IRRMOVQ, IOPQ } : valA; icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : valC; icode in { ICALL, IPUSHQ } : -8; icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ]; ## Select input B to ALU word aluB = [ icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ, IIADDQ } : valB; icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ]; ## Set the ALU function word alufun = [ icode == IOPQ : ifun; 1 : ALUADD; ]; ## Should the condition codes be updated? bool set_cc = icode in { IOPQ, IIADDQ }; ################ Memory Stage ################################### ## Set read control signal bool mem_read = icode in { IMRMOVQ, IPOPQ, IRET }; ## Set write control signal bool mem_write = icode in { IRMMOVQ, IPUSHQ, ICALL }; ## Select memory address word mem_addr = [ icode in { IRMMOVQ, IPUSHQ, ICALL, IMRMOVQ } : valE; icode in { IPOPQ, IRET } : valA; # Other instructions don't need address ]; ## Select memory input data word mem_data = [ # Value from register icode in { IRMMOVQ, IPUSHQ } : valA; # Return PC icode == ICALL : valP; # Default: Don't write anything ]; ## Determine instruction status word Stat = [ imem_error || dmem_error : SADR; !instr_valid: SINS; icode == IHALT : SHLT; 1 : SAOK; ]; ################ Program Counter Update ############################ ## What address should instruction be fetched at word new_pc = [ # Call. Use instruction constant icode == ICALL : valC; # Taken branch. Use instruction constant icode == IJXX && Cnd : valC; # Completion of RET instruction. Use value from stack icode == IRET : valM; # Default: Use incremented PC 1 : valP; ]; #/* $end seq-all-hcl */
以下是该文件编译并通过所有测试的界面:
3.3 第三关
3.31 任务要求
第三关所需的所有工具文件在archlab-handout/sim/pipe目录下。
本关是第一和第二关的综合,让我们通过参考ncopy.c文件中的ncopy函数,根据程序优化相关知识,优化ncopy.ys文件中ncopy函数的汇编代码,使其满足任务要求。
本关可以像第二关一样修改文件pipe-full.hcl,使该Y86-64流水线处理器包含新增的iaddq指令,该指令可以用于ncopy函数的汇编代码,以对其进行优化。
以下为ncopy函数的c语言代码和汇编代码:
// 以下为ncopy.c中的ncopy函数的相关代码 /* $begin ncopy */ /* * ncopy - copy src to dst, returning number of positive ints * contained in src array. */ word_t ncopy(word_t *src, word_t *dst, word_t len) { word_t count = 0; word_t val; while (len > 0) { val = *src++; *dst++ = val; if (val > 0) count++; len--; } return count; } /* $end ncopy */
# 以下为原ncopy.ys中的ncopy函数的相关代码
##################################################################
# Do not modify this portion
# Function prologue.
# %rdi = src, %rsi = dst, %rdx = len
ncopy:
##################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
irmovq $1, %r10
addq %r10, %rax # count++
Npos: irmovq $1, %r10
subq %r10, %rdx # len--
irmovq $8, %r10
addq %r10, %rdi # src++
addq %r10, %rsi # dst++
andq %rdx,%rdx # len > 0?
jg Loop # if so, goto Loop:
##################################################################
# Do not modify the following section of code
# Function epilogue.
Done:
ret
##################################################################
# Keep the following label at the end of your function
End:
#/* $end ncopy-ys */
在修改完pipe-full.hcl文件后,我们需要在目录archlab-handout/sim/pipe下使用其中的makefile文件编译该新的处理器模拟程序,其中模拟程序可以选择tty模式和gui模式,gui模式为makefile文件设置的默认模式,gui模式可以进行单步调试,但需要先安装tty等依赖包,所以我选的是tty模式,可以直接编译该程序而不需要安装依赖包。
改为tty模式的操作就是打开makefile文件并注释掉其中的GUIMODE、TKLIBS和TKINC变量。
在终端程序的archlab-handout/sim/pipe目录下输入指令make psim VERSION=full来编译新的处理器模拟程序。
和第二关一样,编译出了新的处理器模拟程序后,我们需要两轮的漏洞测试(不会测试新加的指令),测试新加的指令会不会使其处理器模拟程序产生漏洞,在终端程序的archlab-handout/sim/pipe目录下先后输入指令./psim -t ../y86-code/asumi.yo和cd ../y86-code; make testpsim来进行小型和大型漏洞测试。
漏洞测试都通过后就可以测试新加指令的逻辑问题了,在终端程序的archlab-handout/sim/pipe目录下先后输入指令cd ../ptest; make SIM=../pipe/psim TFLAGS=-i来进行。
在修改完ncopy.ys文件后,我们需要对其进行测试,测试优化后的代码是否正确并符合要求,如果其使用了新添加的指令,则必须首先要保证新的Y86-64流水线处理器被编译出来并正常无误的运行。
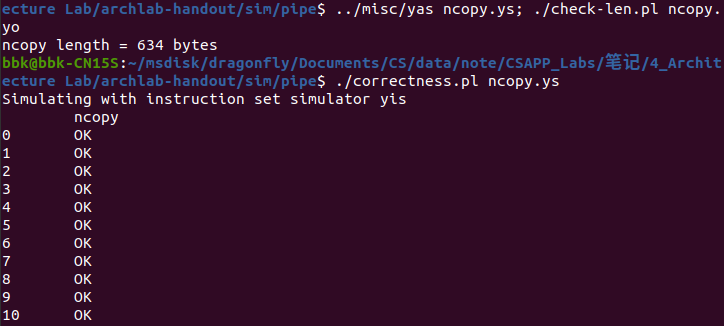
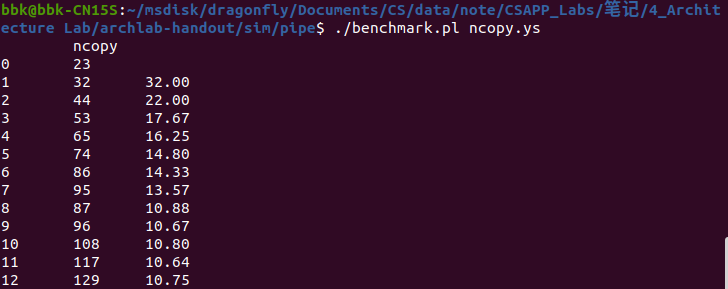
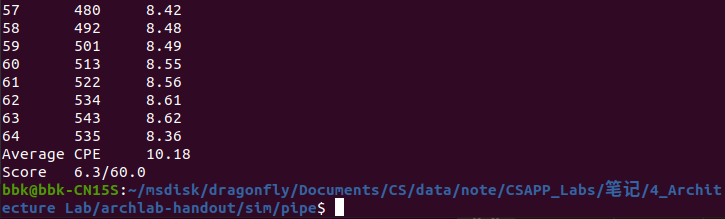
在终端程序的archlab-handout/sim/pipe目录下先后输入指令../misc/yas ncopy.ys; ./check-len.pl ncopy.yo、./correctness.pl ncopy.ys和./benchmark.pl ncopy.ys来进行代码长度检查,代码逻辑检查和代码CPE检查(CPE是测试该文件代码性能的一个指标,表示每复制一个元素所需要的cpu时钟周期,CPE越小就证明该代码复制元素的速度越快)。
任务要求代码长度不能超过1000字节,逻辑要正确没有漏洞,CPE要小于9.00(如果小于7.5则是该代码所能达到的最优性能)。
3.32 任务解答
本关需要对ncopy函数的汇编代码进行优化,使其满足任务要求,通过观察ncopy函数的原始汇编代码,发现该代码的CPE为15.62,所以我们需要添加并使用iaddq指令来优化该代码。
以下为推测出的流水线结构的iaddq指令流程
# iaddq V,rB #phaseFetch # PC <-- {predPC, valA, valM } # icode:ifun <-- M1[PC] # rB <-- M1[PC+1] # valC <-- M8[PC+2] # predPC <-- PC+10 #phaseDecode # valB <-- R[rB] #phaseExecute # valE <-- valC+valB # set CC #phaseMemory # #phaseWriteBack # R[rB] <-- valE
根据推测出的iaddq指令流程,我们就需要在pipe-full.hcl文件中添加或修改对应的hcl变量表达式,具体修改可参考哦笔记中对应的pipe-full.hcl文件。
修改pipe-full.hcl文件后需要进行编译并测试,防止出现漏洞,以下是pipe-full.hcl文件编译并通过所有测试的界面:
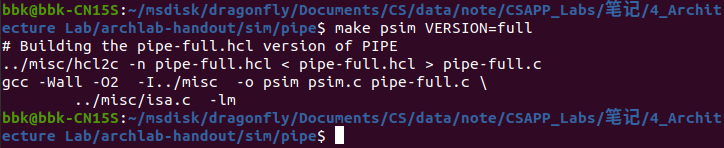
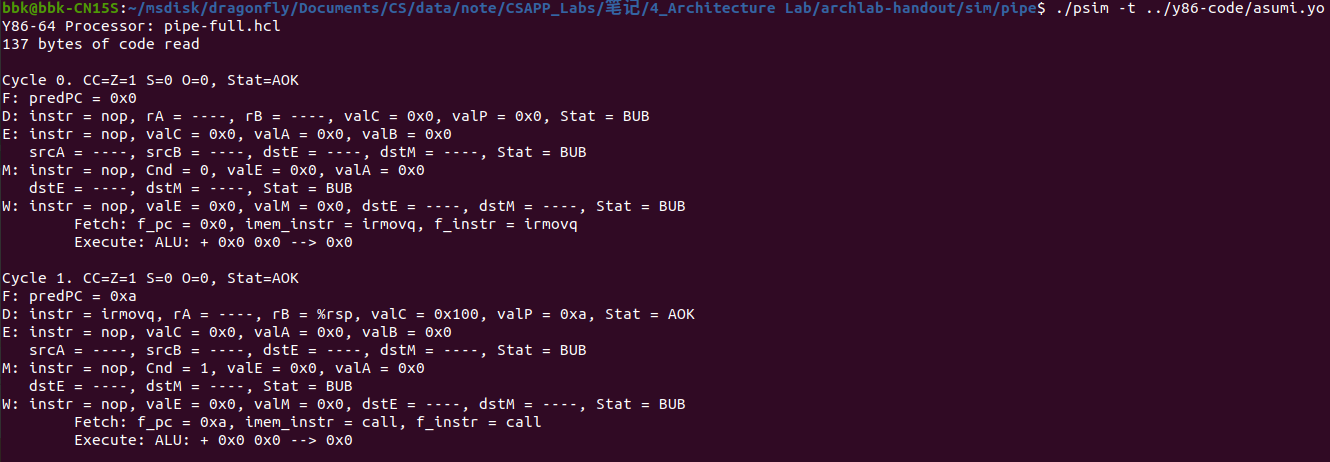
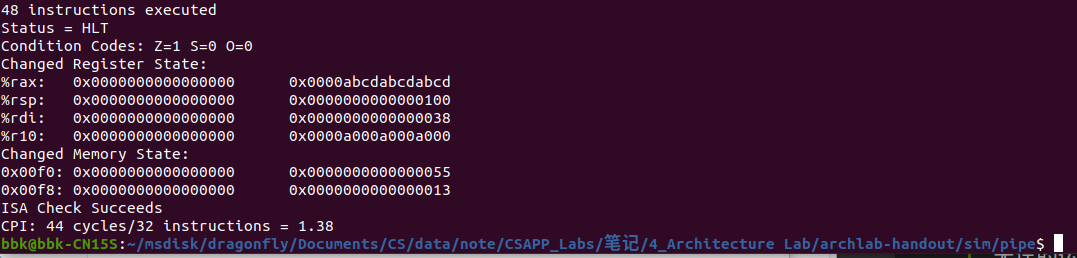
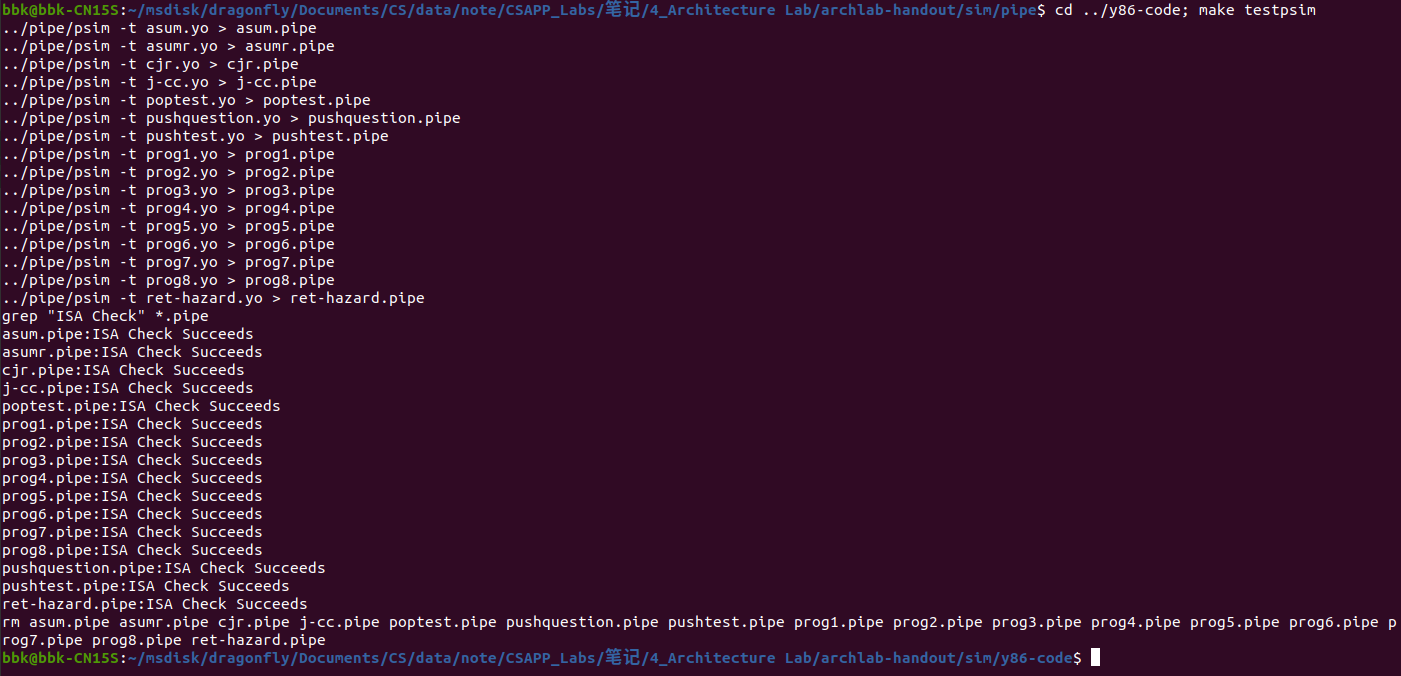

添加完新的iaddq指令后,我们需要对ncopy.ys文件中的函数ncopy进行修改,优化该代码,其中我们可以看到用了一个条件跳转指令来表示循环,我们可以根据程序优化相关知识,将其调整为循环展开,从而减少循环判断等指令操作的次数。
以下为优化后的汇编代码:
# 以下为修改后的ncopy.ys中的ncopy函数的相关代码,经测试,展开8次是最优的,多了少了都会增加CPE。
##################################################################
# Do not modify this portion
# Function prologue.
# %rdi = src, %rsi = dst, %rdx = len
ncopy:
##################################################################
# You can modify this portion
# Loop header
rrmovq %rdx, %r9 # loop unroll variable
iaddq $-7, %r9 # for loop unroll
xorq %rax,%rax # count = 0;
jmp mainTest # goto mainTest
mainLoop:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump1 # if so, jump the count
iaddq $1, %rax # count++
jump1:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump2 # if so, jump the count
iaddq $1, %rax # count++
jump2:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump3 # if so, jump the count
iaddq $1, %rax # count++
jump3:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump4 # if so, jump the count
iaddq $1, %rax # count++
jump4:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump5 # if so, jump the count
iaddq $1, %rax # count++
jump5:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump6 # if so, jump the count
iaddq $1, %rax # count++
jump6:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump7 # if so, jump the count
iaddq $1, %rax # count++
jump7:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
andq %r10, %r10 # val <= 0?
jle jump8 # if so, jump the count
iaddq $1, %rax # count++
jump8:
iaddq $-8, %r9 # decrease amount of limit
iaddq $-8, %rdx # decrease amount of len
mainTest:
andq %r9,%r9 # len > 0?
jg mainLoop # if so, goto mainLoop:
jmp restTest # goto restTest
restLoop:
mrmovq (%rdi), %r10 # read val from src...
iaddq $8, %rdi # src++
rmmovq %r10, (%rsi) # ...and store it to dst
iaddq $8, %rsi # dst++
iaddq $-1, %rdx # len--
andq %r10, %r10 # val <= 0?
jle restTest # if so, jump the count
iaddq $1, %rax # count++
restTest:
andq %rdx,%rdx # len > 0?
jg restLoop # if so, goto restLoop:
##################################################################
# Do not modify the following section of code
# Function epilogue.
Done:
ret
##################################################################
# Keep the following label at the end of your function
End:
#/* $end ncopy-ys */
以下是优化后的ncopy.ys文件通过所有检查的界面(非满分):

4.总结
本次实验让我们深入地认识并了解了处理器的指令结构以及实现其指令架构的相关知识。
通过这次实验,我们在以后的编写代码时能够从处理器指令的方面考虑代码编写所花费的时间与空间,这样能够让我们写出时间更快,内存更少的程序。